优化 Elasticsearch IK 分词器对于英文不准确问题 时间: 2021-05-01 19:35 分类: JAVA ####前言 经过一天的摸索,总算大致满足了现有的搜索需求。 不知道为什么`ik_analyzer`被吹嘘的那么牛皮,而实际上是根本无法直接用来线上使用的。 说下它的一个致命问题吧,那就是对于`数字+中英文`混合的词组,尽管配置了扩展词库,还是会将其拆分。 ####问题分析 在 github 上有人说使用远程词库可以解决,试了下的确可以,但也有人说部分还是不行。 这个问题暂且配置成远程词库勉强解决。 还有个问题就是`小数点`的问题,对于英文它好像总是以空格来进行分词的,因此如果有字符串`Mickey.Donald.Goofy.The.Three.Musketeers.2004.BDRip.720p.mkv`,使用`ik_smart`分析器进行分析,将只得到原始的字符串一个分词: 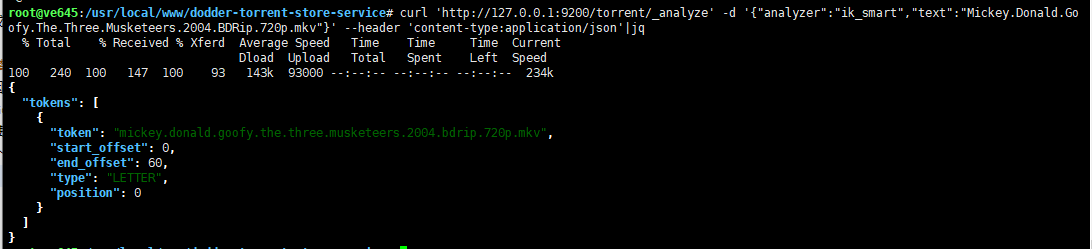 是不是感觉巨坑,`小数点`竟然不是`stopword`,看到这里,首先想到的就是手动去配置扩展`stopwords`。 但是无论是配置本地还是远程`stopwords`,都不起作用!注意:不是说配置不生效,而是对于`小数点`特殊,直接给忽略了,比如配置`,`逗号,将刚才的字符串小数点全改成逗号,再次分析,发现扩展`stopword`是生效的。 上面说的是使用`ik_smart`分词器,如果是`ik_max_word`呢,照样还是有问题的: 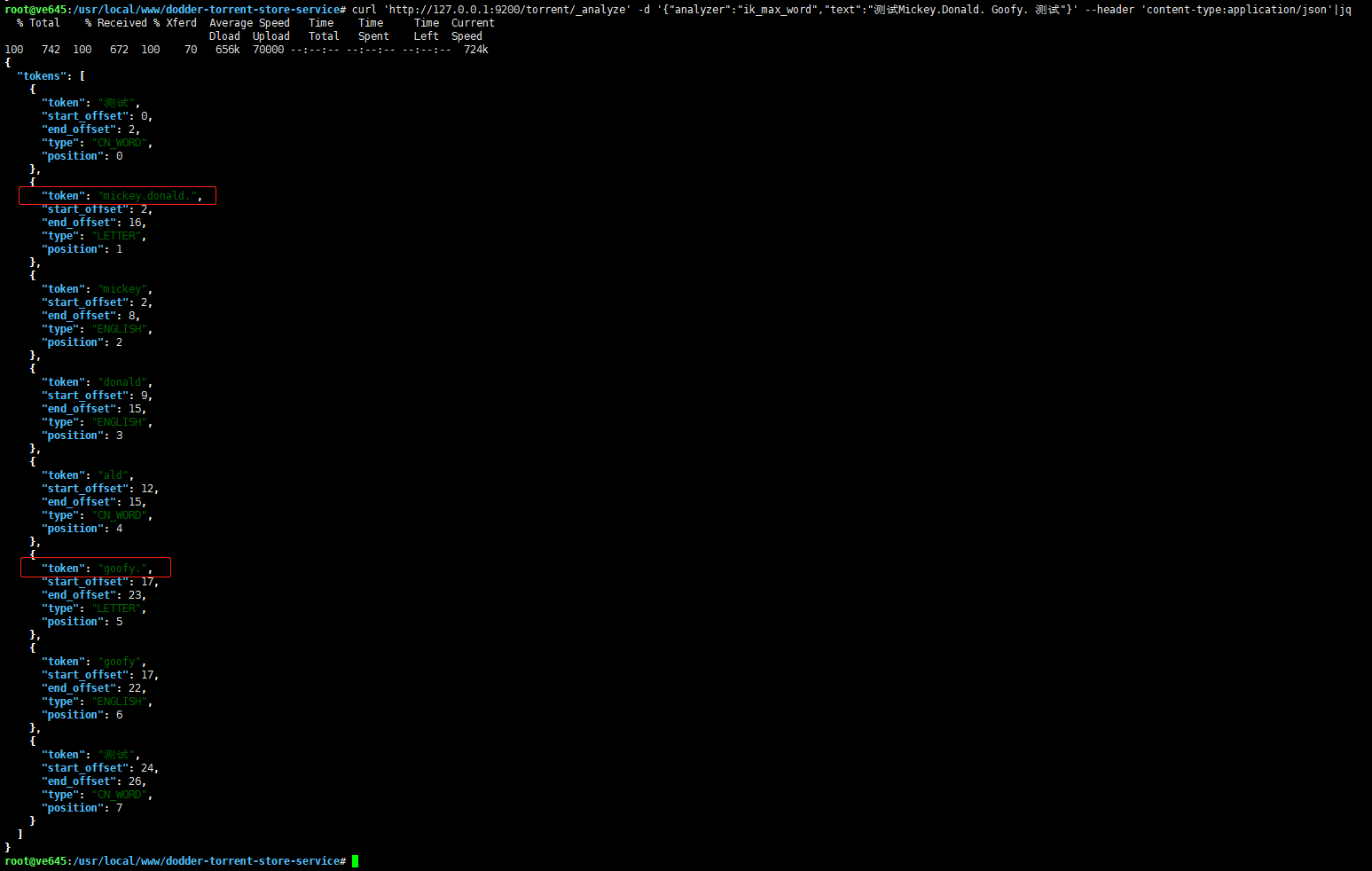 可以看到,分词结果确实变多了,`小数点`也确实处理了,但是处理的不够彻底,图中标记部分是什么鬼? 仔细想一下,它还是遇到空格后就将`小数点`划分进单词里面去了,虽然对搜索没有影响,这下可以单个词语搜索成功了,但是这明显浪费磁盘和内存吗,这些不必要的分词应该去掉! 知道了问题所在,那么就该解决问题了,改源码吗?不太现实,就算有那技术,恐怕你也没那个时间去分析其代码。 于是经过一番搜索,查看官方文档,可以通过配置`char_filter`来解决这个问题: ``` { "index": { "number_of_shards": "2", "number_of_replicas": "0", "refresh_interval": "1m" }, "analysis": { "analyzer": { "comma": { "type": "pattern", "pattern":"," }, "my_ik_smart": { "type": "custom", "tokenizer": "ik_smart", "filter": [ "stemmer" ], "char_filter": [ "dot_char_filter" ] }, "my_ik_max_word": { "type": "custom", "tokenizer": "ik_max_word", "filter": [ "stemmer" ], "char_filter": [ "dot_char_filter" ] } }, "char_filter": { "dot_char_filter": { "type": "pattern_replace", "pattern": "\\.", "replacement": " " } } } } ``` 大致思想就是:对于 IK 分词结果进行再分词处理,这里就是将 IK 分词结果中的`.`替换成空格,而 IK 分词器对于空格是敏感的,所以就完美解决了上面的问题,再次测试: 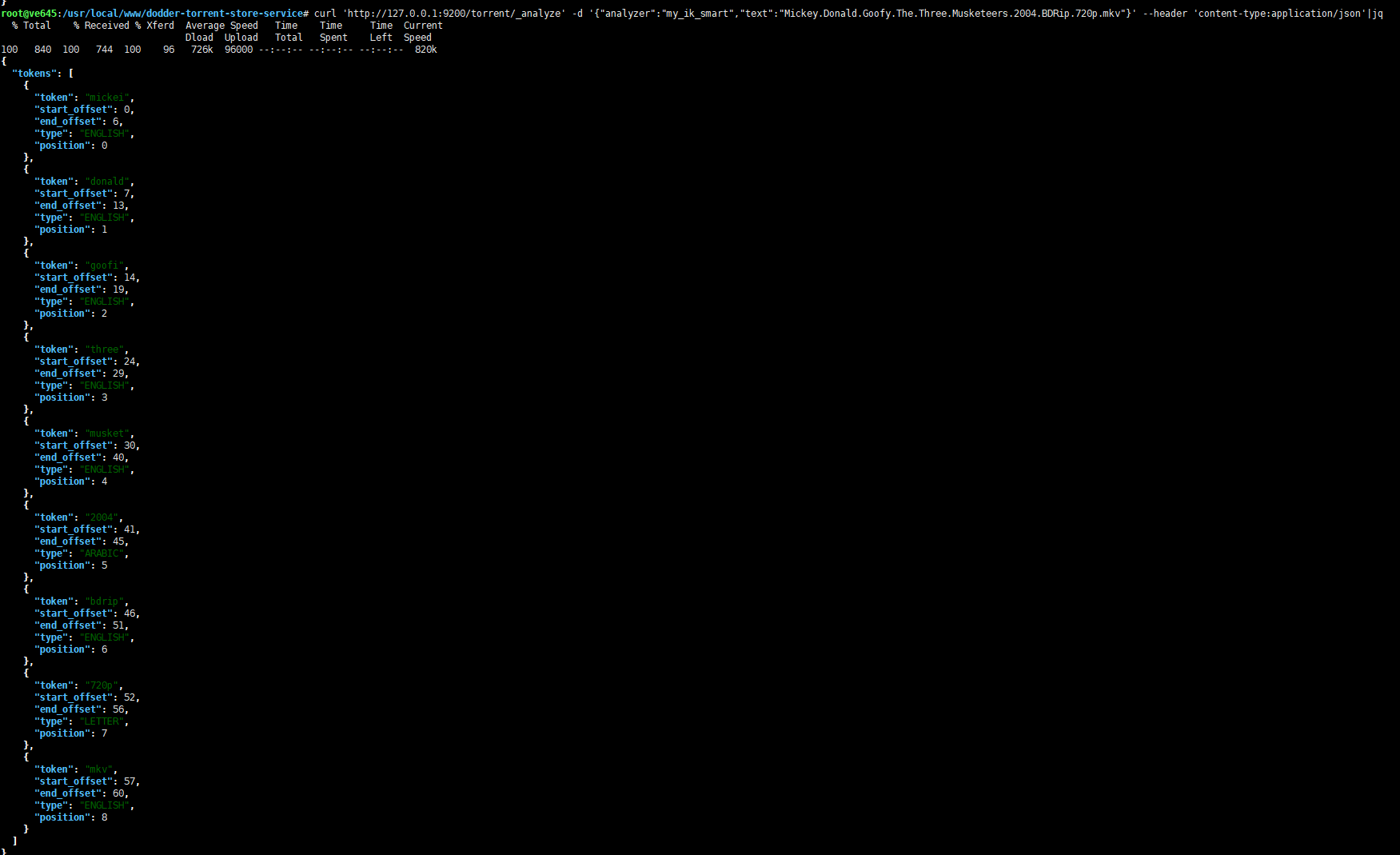 `ik_smart`正常了。 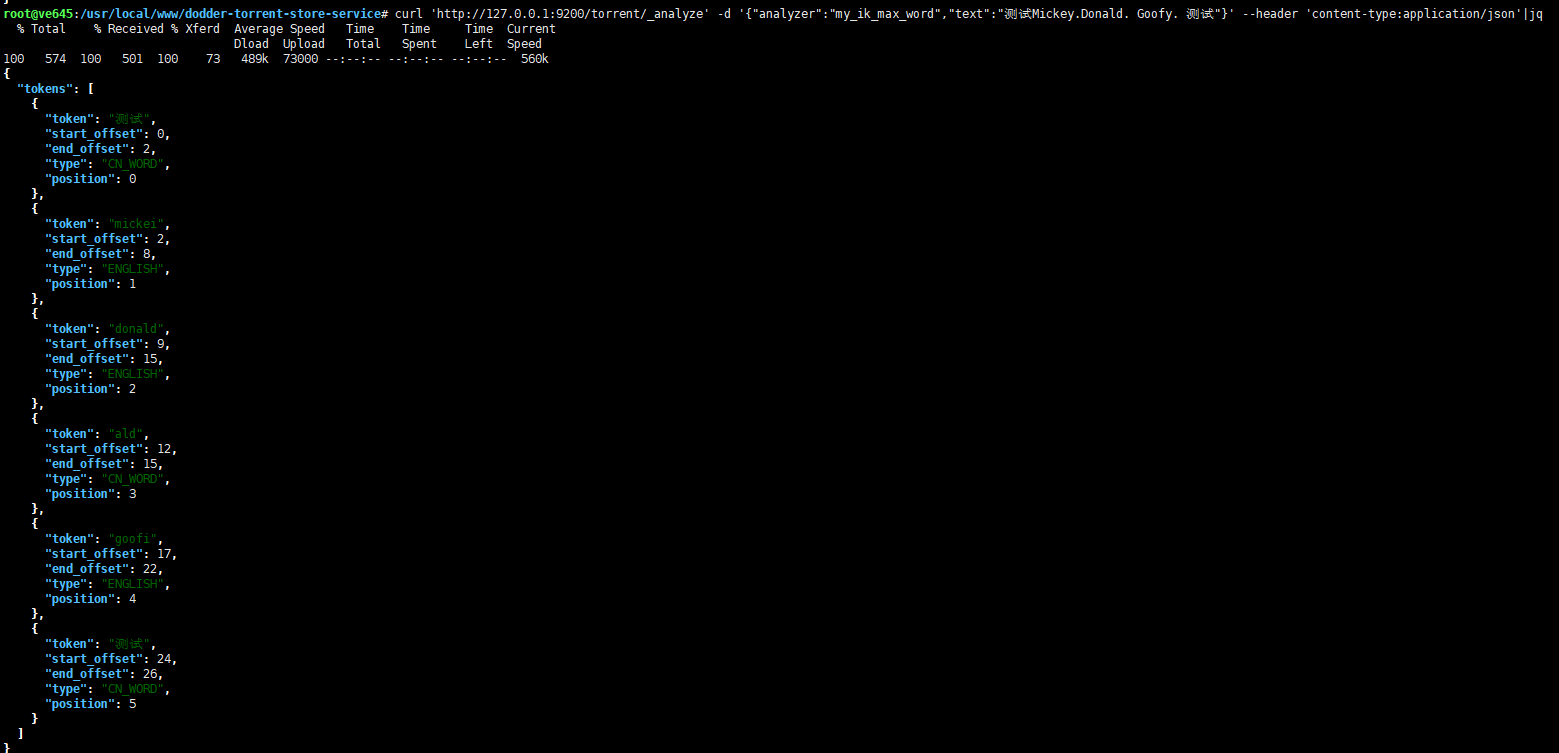 `ik_max_word`中多余的分词也没有了,至于为什么`Goofy`变成了`goofi`,是因为是用了`stemmer`这个`filter`。 它也能弥补`IK分词器`对于英文复数处理的不足。相应的还有`synonym`过滤器用来处理同义词,根据自己需求来决定是否需要。 标签: 无