浅谈 Java 垃圾回收机制 时间: 2018-03-14 18:30 分类: JVM ####概述 说起 Java 的特点,很容易就会联想到它的垃圾回收机制,这是要与 C/C++ 主要区别之一的地方。很多人都是因为 C/C++ 中的指针及内存需要我们手动释放和转向了 Java 的怀抱。 首先需要思考的是 GC 需要完成的三件事情: * 哪些内存需要回收? * 什么时候回收? * 如何回收? ####浅述垃圾回收对象判断 针对第一个问题`哪些内存需要回收?` 在 java 中说得通俗易懂些就是哪些对象会被认为是垃圾对象(已死的对象),或者就是大家常说的不存在对该对象引用的对象。 一个比较容易想到的算法就是`引用计数法`,这也是关于如何判断一个对象是无用对象问题大多数人回答的答案。 #####引用计数法 该算法的做法就是给对象添加一个引用计数器,当有对象引用它时就把计数器加一,当引用失效时,就把计数器减一。 该算法简单暴力,效率也比较高,但是对于`相互循环引用`的对象则会出现问题: ```java public class ReferenceCountingGC { public Object reference = null; //用来便于查看GC信息 private byte[] buff = new byte[2 * 1024 * 1024]; public static void main(String[] args) { ReferenceCountingGC a = new ReferenceCountingGC(); ReferenceCountingGC b = new ReferenceCountingGC(); a.reference = b; b.reference = a; a = null; b = null; System.gc(); } } ``` 可以看到上面代码,a 引用了 b, b 也引用了 a,此时我们分析下如果用引用计数法 a 和 b 在执行到 10 行时候的引用计数器是多少: 9、10 行创建新对象,a 与 b 此时各自引用了一个 ReferenceCountingGC 对象,即此时新建了两个 ReferenceCountingGC 对象,每个 ReferenceCountingGC 对象的引用计数器值为 1。 12、13 行将其互相引用,此时两个 ReferenceCountingGC 对象各自增加了一个 reference 对其的引用,所以引用计数器值都变成了 2。 15、16 行将 a 和 b 两个对 ReferenceCountingGC 对象的引用清除,此时 9、10 行新建的两个 ReferenceCountingGC 已经再也无法访问了,但是此时两个 ReferenceCountingGC 对象的引用计数器各自减 1,值为 1,若用引用计数法的话,这两个 ReferenceCountingGC 对象将永远无法回收。 而实际上,上面的代码在 java 虚拟机中最终是会进行回收的。如何确定它是否回收请看下面做法: 将 15、16 行注释,运行参数加上`-verbose:gc`查看 GC 信息如下: >[GC (System.gc()) 7428K->4976K(125952K), 0.0018914 secs] [Full GC (System.gc()) 4976K->4735K(125952K), 0.0053039 secs] 可以看到 GC 前后程序所占的内存相差不大。 然后将 15、16 行取消注释,再次运行,查看结果如下: >[GC (System.gc()) 7428K->848K(125952K), 0.0009369 secs] [Full GC (System.gc()) 848K->640K(125952K), 0.0051655 secs] 此时看到 GC 后程序所占内存明显下降,也就是说回收了 9、10 行新建的两个 ReferenceCountingGC 对象。 所以说 Java 中并非是采用`引用计数法`来判断对象是否可以回收的。 #####可达性分析法 Java 采用的就是该算法来判断对象是否可回收的。这个算法的基本思想就是通过一系列的成为`GC Roots`的对象作为起点,从这些节点往下搜索,搜索所走过的路径称为`引用链`,当一个对象到`GC Roots`没有任何`引用链`时,则证明该对象是不可用的,如下图,Obj5 虽然和 Obj6、Obj7 有关联,但是到`GC Roots`是不可达的,所以会被判定为是可回收的垃圾对象: 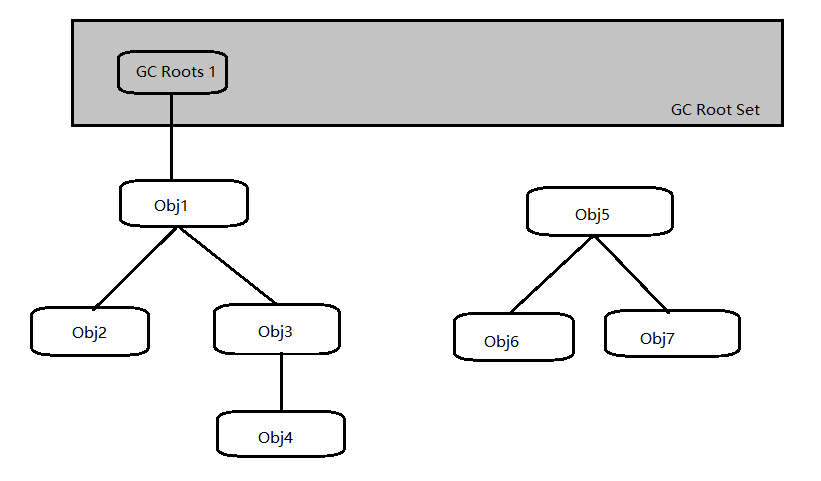 在 Java 中,可作为`GC Roots`的对象包括如下几种: * 虚拟机栈(栈帧中的本地变量表)中引用的对象。 * 方法区中静态变量属性引用的对象(即类中的静态变量)。 * 方法区中常量引用的对象(即 final 修饰的变量)。 * 本地方法栈中 JNI (即 native 方法)引用的对象。 ####浅述垃圾收集算法 关于第二个问题,垃圾对象什么时候回收就不多说了,记住回收时间是不确定的,程序员是无法手动回收,只能提醒虚拟机回收即可。 第三个问题`如何回收`,讲的也就是垃圾收集算法。 #####1、标记 - 清除算法 该算法从名字上看就知道,有两个过程: * 标记:找到所有可访问的对象,做个标记 * 清除:遍历堆,清除所有未标记的对象 该算法存在两个问题: * 效率问题,标记和清除两个过程效率都不高 * 空间问题,标记清除后会产生大量的内存碎片,图片就不画了,打个比方,一段连续的内存 1、2、3、4、5、6...,现发现 2、4、6 对象可回收,回收之后 1、3、5 之间将会产生间隙,大对象无法再次分配到这三个内存碎片上面。 #####2、复制算法 为了解决前面的效率问题,于是出现了`复制`算法,该算法的基本思想就是把可用内存分为大小相同的两块,每次只是用其中一块内存(即把可用内存缩小了一般),当这块内存用完了,就把该块内存上还存活的对象复制到另一块上面去,然后一次性清理掉这块内存,这样子就是每次对整个可用内存的半区进行回收,实现简单,运行高效。不像上面的`标记 - 清除算法`需要搜索标记与遍历清除。 该算法存在的缺点就是:牺牲了可用内存大小,将其变成了一半,即浪费了一半的内存空间。 新生代使用该种算法,因为新生代中对象都是“朝生夕死”的那种,所以需要复制的对象较少,效率也就较高。 HotSpot JVM 把年轻代分为了三部分:1 个`Eden`区和 2 `Survivor`区(分别叫from和to),默认比例为 8:1。 每次使用`Eden`和其中一块`Survivor`,这样就确保了每次新生代中可用内存为整个新生代容量的 90%(80% + 10%),只有 10% 的内存会被浪费。 当发生 GC 的时候,会将 `Eden` 区中的所有存活对象复制到 `Survivor to`块中去,而`Survivor from`中的存活对象则根据其年龄移动到不同的地方去,年龄到达一定值会复制到老年代去,否则复制到 `Survivor to`块中去,然后`Survivor to`与`Survivor from`交换角色,清理内存,也就是总是保证`Survivor to`内存区域是空的。当然了,由于`Eden`块占 80%,可能会出现`Eden`块与`Survivor from`中存活对象所占的内存超过 10%, 这时候就需要去老年代借内存,这个过程叫做分配担保。 #####3、标记 - 整理算法 上面的`复制算法`如果用在老年代会怎样? 老年代的对象一半都是些生命周期较长的对象,所以如果用`复制算法`的话会出现频繁复制的问题。 所以针对老年代就有了`标记 - 整理算法`,该算法的基本思想和`标记 - 清除算法`差不多,但是更高效。 做法如下: * 标记可访问对象,全部向内存某一端移动。 * 清理可访问对象另一端的所有内存空。 ####总结 主要学习了 Java 中垃圾对象的判断算法以及垃圾收集算法。 * 引用计数器算法 * 可达性分析算法 * 标记 - 清除算法 * 复制算法 (新生代) * 标记 - 整理算法 (老年代) 标签: gc